Después de un apagado brusco del equipo de casa que hace las funciones de NAS, tras el reinicio noté que iba realmente lento, así que revisé varios parámetros del sistema operativo tales como consumo de CPU, RAM …
top – 20:38:33 up 1:15, 2 users, load average: 1.64, 1.74, 1.78
Tasks: 238 total, 1 running, 236 sleeping, 0 stopped, 0 zombie
Cpu(s): 30.9%us, 10.2%sy, 0.0%ni, 55.0%id, 3.3%wa, 0.0%hi, 0.6%si, 0.0%st
Mem: 8049492k total, 5032520k used, 3016972k free, 588176k buffers
Swap: 14651244k total, 0k used, 14651244k free, 1624444k cached
… tiempos de acceso a disco …
root@nas:/home/angel# hdparm -Tt /dev/md0
/dev/md0:
Timing cached reads: 2584 MB in 2.00 seconds = 1291.84 MB/sec
Timing buffered disk reads: 1054 MB in 3.00 seconds = 350.92 MB/sec
.. estado del raid software …
root@nas:/home/angel# mdadm –detail /dev/md0
/dev/md0:
Version : 0.90
Creation Time : Mon Mar 22 18:25:59 2010
Raid Level : raid5
Array Size : 4351454016 (4149.87 GiB 4455.89 GB)
Used Dev Size : 1450484672 (1383.29 GiB 1485.30 GB)
Raid Devices : 4
Total Devices : 4
Preferred Minor : 0
Persistence : Superblock is persistentUpdate Time : Fri May 4 20:28:10 2012
State : active, resyncing
Active Devices : 4
Working Devices : 4
Failed Devices : 0
Spare Devices : 0Layout : left-symmetric
Chunk Size : 64KResync Status : 23% complete
UUID : a2817b06:93997583:1f5ed1ed:1da3d5c1
Events : 0.123774Number Major Minor RaidDevice State
0 8 2 0 active sync /dev/sda2
1 8 18 1 active sync /dev/sdb2
2 8 34 2 active sync /dev/sdc2
3 8 50 3 active sync /dev/sdd2
root@nas:/home/angel# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4] [linear] [multipath] [raid0] [raid1] [raid10]
md0 : active raid5 sda2[0] sdc2[2] sdd2[3] sdb2[1]
4351454016 blocks level 5, 64k chunk, algorithm 2 [4/4] [UUUU]
[=====>……………] resync = 25.1% (364361728/1450484672) finish=224.5min speed=80617K/sec
unused devices: <none>
… el problema es una reconstrucción del raid software, ¿motivo? El syslog nos lo aclara …
May 4 19:24:14 nas kernel: [ 2.188980] md/raid:md0: not clean — starting background reconstruction
May 4 19:24:14 nas kernel: [ 2.188993] md/raid:md0: device sda2 operational as raid disk 0
May 4 19:24:14 nas kernel: [ 2.188996] md/raid:md0: device sdc2 operational as raid disk 2
May 4 19:24:14 nas kernel: [ 2.188998] md/raid:md0: device sdd2 operational as raid disk 3
May 4 19:24:14 nas kernel: [ 2.189000] md/raid:md0: device sdb2 operational as raid disk 1
May 4 19:24:14 nas kernel: [ 2.189442] md/raid:md0: allocated 4280kB
May 4 19:24:14 nas kernel: [ 2.189480] md/raid:md0: raid level 5 active with 4 out of 4 devices, algorithm 2
May 4 19:24:14 nas kernel: [ 2.189518] md0: detected capacity change from 0 to 4455888912384
May 4 19:24:14 nas kernel: [ 2.189690] md: resync of RAID array md0
May 4 19:24:14 nas kernel: [ 2.189704] md: resuming resync of md0 from checkpoint.
Aprovecho para revisar características de interés en dispositivos de almacenamiento tales como MTTR, en éste caso que no se trata de un sistema en fallo ya que puedo acceder a los volúmenes del raid, pero si está en modo degradado ya que el rendimiento del equipo está afectado. El tiempo para que la reconstrucción del raid finalice y pasar al estado operacional en éste caso es el MTTR (Mean Time to Repair).Más referencias en éste artículo.
Del syslog mostrado anteriormente tenemos que el raid empezó la resincronización a las "19:24:14", la finalización de la reconstrucción del raid se observa en el syslog a las "1:25:38":
May 5 01:25:38 nas mdadm[1372]: RebuildFinished event detected on md device /dev/md0, component device mismatches found: 16 (on raid level 5)
En resumen el MTTR del equipo cuando su raid software está degradado y liberarlo de un estado "not clean" es aproximadamente 6 horas.
Éste parámetro es ampliamente usado en la industria de cabinas de almacenamiento pero en otro caso, fallo de un disco en raid, al igual que MTTF (Mean Time to Failure) y MTBF (Mean Time Between Failures). Siendo el MTTF el tiempo que permanece sin errores de disco y MTBF se trata de el tiempo que hay entre dos errores de disco. Ésta gráfica resume de forma sencilla el ciclo de error que definen éstos parámetros:
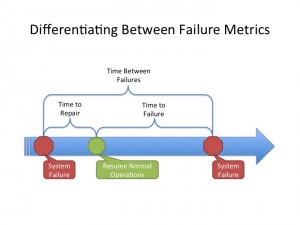
Por suerte, en el caso del NAS casero no he calculado el valor real del MTTF, MTTR y MTBF de discos en fallo ya que desde que lo monté por Octubre del 2009 y con uso continuo no he tenido errores de disco, con una excepción de sectores en fallo en uno de los discos nuevos que solventé con los pasos de este post. Además el equipo no dispone Hot Spare para el RAID 5 por lo que un disco en fallo significará que operará en modo degradado hasta que lo sustituya y finalice con la reconstrucción del nuevo. En este caso el MTTF real tiene un componente humano … 😛